GCPにおけるデータモデリングの実践と最適化
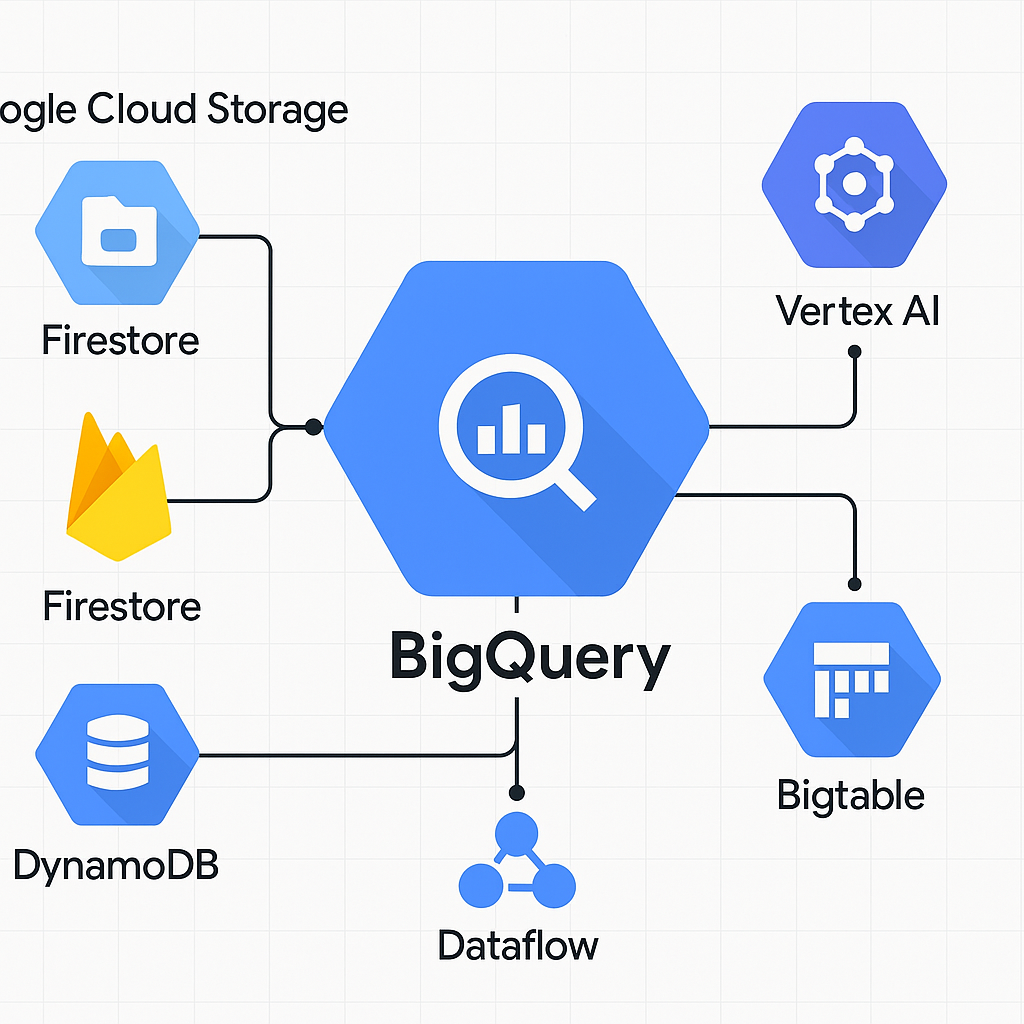
Google Cloud Platform(GCP)は、スケーラブルで高可用性なインフラと、強力なビッグデータ・AIサービスを組み合わせて、柔軟なデータ活用が可能なクラウドプラットフォームである。
GCPでのデータモデリングは、データベース単体の設計にとどまらず、BigQuery、Cloud Storage、Pub/Sub、Dataflow、Vertex AI などの連携を通じて、ストレージ・処理・分析・機械学習が一体化した“全体設計”が求められる。
1. GCPにおける主要データサービス
- BigQuery:ペタバイト級のデータを高速処理できるサーバーレスDWH。分析基盤の中核
- Cloud Storage:非構造化データの保管。データレイクやバックアップ用途
- Cloud SQL / AlloyDB:構造化データのトランザクション処理(PostgreSQL, MySQLベース)
- Firestore / Datastore:NoSQLデータベース。モバイル/IoT用途
- Pub/Sub:イベント駆動のストリーム処理用メッセージキュー
- Dataflow / Dataproc:ETL処理、ストリーム処理(Apache Beam, Spark)
- Vertex AI:AI/MLの学習・予測基盤
2. モデリング戦略とアーキテクチャ設計
GCPの強みは "バッチ・ストリーム・ML" がすべて統合可能な点にある。以下のようなマルチレイヤ構造を想定したモデル設計が理想である。
- 原始データレイヤ(Raw):Cloud Storage にログ・センサーデータ・CSVなどを保存
- 整形データレイヤ(Staging):Dataflowでクレンジング・変換し、BigQueryステージングテーブルへ格納
- 分析レイヤ(Analytics):正規化または非正規化された分析用テーブル群(スター型、パーティション型)
- 機械学習レイヤ(ML Feature Store):Vertex AI Feature Storeに特徴量を管理し、モデルに接続
ある通信キャリアでは、モバイルアプリのイベントデータをPub/Subで受信、Dataflowでリアルタイム加工後、BigQueryで分析。月間200億件以上のデータを処理し、ユーザー行動分析と解約予測モデルに活用している。
3. BigQueryのモデリングベストプラクティス
- 非正規化を基本とし、JOINを最小限に
- パーティション化:日付(event_date)、ID(hash_partitioning)によるコスト最適化
- クラスタリング:クエリフィルタに使用されるカラム(user_id、categoryなど)で設定
- RECORD型(ネスト構造):JSON型データやリスト形式をそのまま取り込める
- Materialized View / View:再利用性・性能向上を意識したクエリ構造
4. GCPモデリング事例:Eコマース基盤
- Rawログ:Cloud Storageに保存(Parquet形式推奨)
- イベント整形:DataflowでJSON→フラットテーブルへ変換
トランザクションテーブル(BigQuery)
- transaction_id, user_id, product_id[], purchase_time, total_price
ユーザーテーブル(Cloud SQL)
- user_id, name, address, last_login
商品テーブル(BigQuery + Cloud Storage画像)
- product_id, name, category, stock, image_url
ML予測対象(Vertex AI)
上記構成を使った企業では、プロモーション対象顧客をAIで抽出し、Gmail APIと連携して1日30万通のパーソナライズドキャンペーンを自動配信している。
5. 実装時の注意点と改善アプローチ
- クエリコストの可視化と制限:
INFORMATION_SCHEMA.JOBSを使ってスキャンバイト監視 - セキュリティ設計:IAM, Row-level security, Column encryption を適切に設計
- レイクハウスアーキテクチャ対応:BigLakeテーブルでStorageとBigQueryの一元化
- スキーマ進化の設計:nullable設計、バージョン付きView設計
特に大量ユーザーを扱うWebアプリでは、匿名データを含むデータレイクと、PII管理されたウェアハウスを分離管理するのが主流である。
まとめ
GCPにおけるデータモデリングは「システム連携」「データレイク・ウェアハウス統合」「リアルタイム性とML活用の両立」が問われる高度な設計技術である。
BigQueryを中核に、Pub/Sub・Dataflow・Vertex AI・Cloud Storageを目的に応じて組み合わせ、ETLからBI、予測分析までを一気通貫で設計できる点が最大の魅力である。
今後は BigLake, AlloyDB, Duet AI などとの連携を視野に入れ、「変化に強く、使いやすく、拡張可能なモデル設計」が求められていく。